2024年 アメリカの中国からの輸入額(百万ドル)をpycaretを使ってやってみる。
元データのダウンロード、および変数詳細は、前の記事参照。
# データの読み込み
df = pd.read_csv('china_dummy.csv')
ML2 = df[['Date','Value',"Tax", "COV19"]]
ML2['Date'] = pd.to_datetime(ML2["Date"])
ML2 = ML2.set_index('Date')
ML2
# 時系列としてライブラリーを読み込み
from pycaret.time_series import *
# テスト期間を12ケ月でセット、データ概要
exp_name = setup(data=ML2, target='Value', fh=12, session_id=1)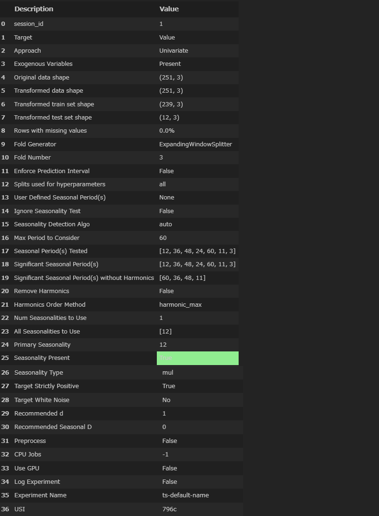
# 最適モデルの探索 ___ 計算に少し時間がかかる。
best_model = compare_models()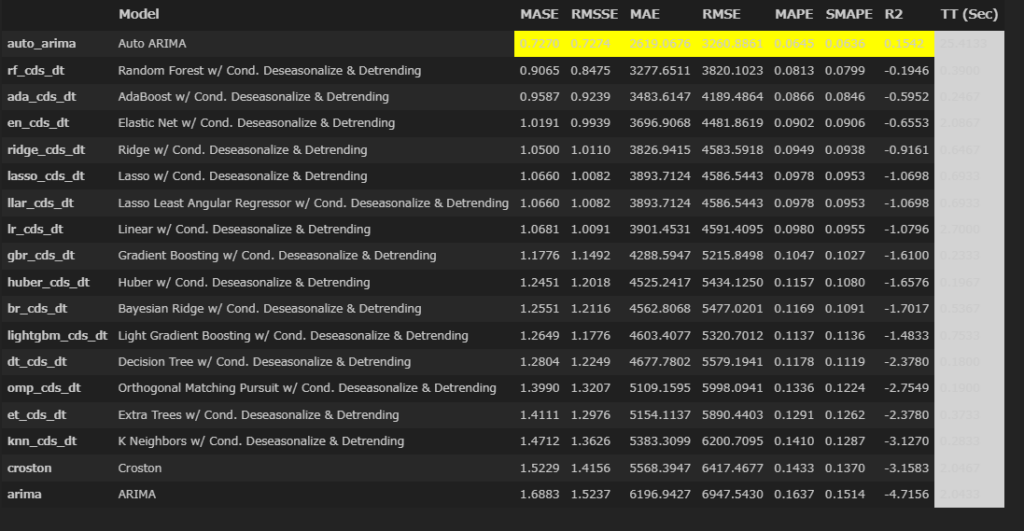
モデルとしては、auto_arimaが一番いいとの選択。RMSE(二乗平均平方根誤差)は3261(百万ドル)、MAPE(平均絶対パーセント誤差)は6.3%。悪くはないが特別よくもない。
# 輸入額、関税、コロナダミーの描画
plot_model(plot="ts")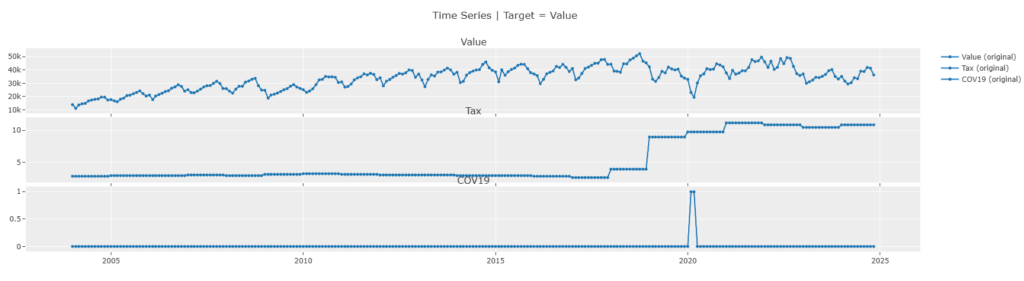
# SLT分解
plot_model(plot="decomp")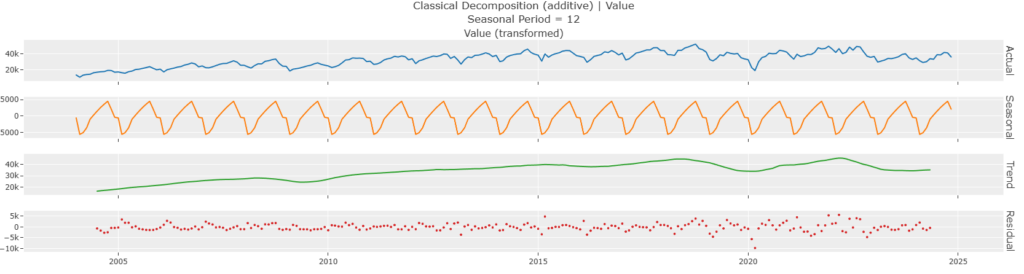
12ケ月単位の周期性あり。
# auto_arimaでモデル設定
plot_model(estimator=auto_arima, plot="forecast", data_kwargs={"fh":12})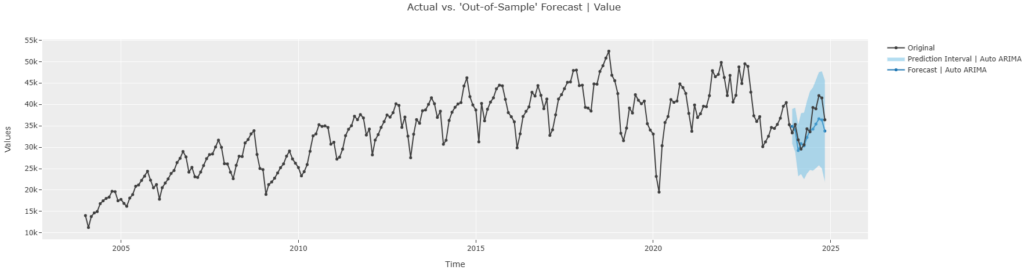
2024年の前半はよくフィットしているが、後半はすれが大きいと思われる。評価を見てみる。
auto_arima = create_model("auto_arima")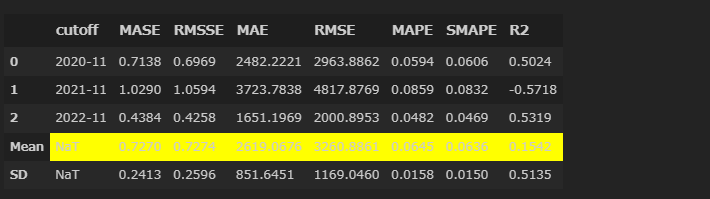
2021年前後のぶれが大きい。やはりコロナ時期の変動の影響か?RMSEを最小にするようにチューニングをしてみる。
# RMSEでチューニング _______ 計算に無茶苦茶時間かかる
tuned_auto_arima = tune_model(auto_arima, n_iter=5, optimize="RMSE") 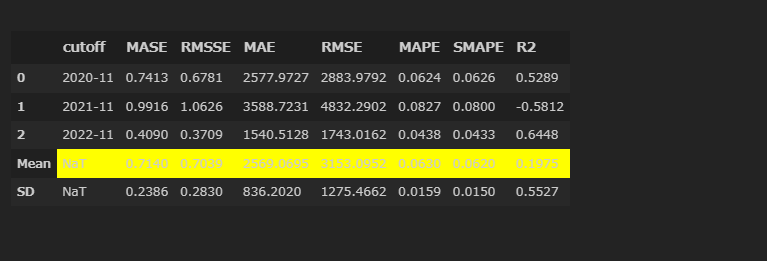
RMSEが3153百万ドル、MAPEは6.3%へと若干改善。
# 再度、描画
plot_model(estimator=tuned_auto_arima, plot="forecast", data_kwargs={"fh":12})
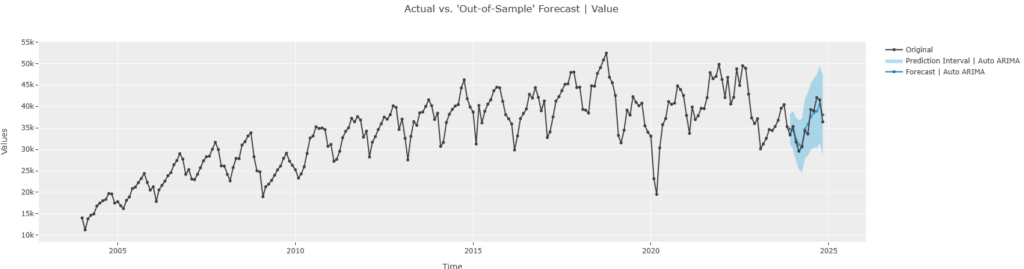
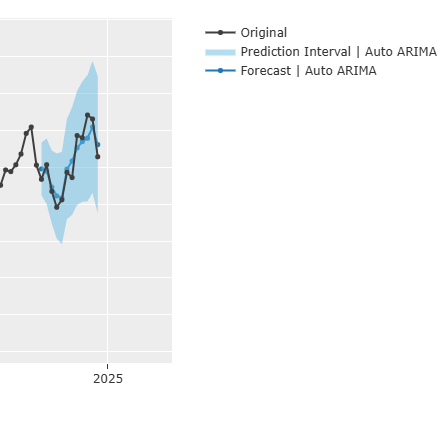
2024年後半が改善し、もっとフィットするようになった。
【注記】
データの引用元は、ITC (U.S. International Trade Commission)。
輸出額は、ITC データベースの輸出合計 (Exports: Total)。
輸入額は、後日、関税率などを算定すること等もあり、一般輸入額 (Imports: General)ではなく、消費用輸入額 (Imports: Consumption)の関税評価額(Customs Value)を引用している。