アメリカの中国からの輸入額(百万ドル)は、2018年後半からコロナ禍+トランプ第一期政権の関税という二つの影響を受けて大きく変動している。そこで、機械学習で、それらの影響を少しでも分析できないかやってみる。もちろん、現実は、残ざまな要因が複雑に絡み合っているので、単純ではないが、モデル化のために、非常にシンプルなモデルでとりあえずやってみる。
データとして、2002年1月から2024年11月までの中国からの月次輸入額(百万ドル)と、関税率想定(個別の関税率ではなく、各分野の輸入額と課税額からの平均関税率、さらにコロナ禍で輸入額が落ちた月をコロナ禍の影響としてダミー変数(1)とした。
元データは以下↓
各変数の設定は以下のとおり
| 変数 | 説 明 |
| Date | 年月日形式の日付(各月末の集計であるが、便宜上、各月1日としている) |
| Year | 年 |
| Month | 月 |
| Value | アメリカの中国から月次の輸入額(百万ドル) |
| Tax | 推定平均関税率(%) |
| Tax2 | 推定平均関税率(%)(2019年以降なしの場合の推定用に2019年1月以降、2018年の平均4%のままとしている) |
| COV19 | ダミー変数(コロナ禍の影響で大きく額が落ち込んだ2020年2月、3月を1、それ以外を0としている) |
想定関税率想定は以下の記事を参照ください。
単回帰
まずは、コロナ禍と関税を考慮せずに、輸入額のみで単回帰をやってみる。
# ライブラリーの読み込み
from sklearn.linear_model import LinearRegression as LR
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import japanize_matplotlib
# 時系列の特性を意識しないで回帰分析
year = df['Year'].values
month = df["Month"].values
year = year + (month - 1) / 12# 単回帰
model1 = LR()
model1.fit(year.reshape(-1, 1), df["Value"])
y_pred1 = model1.predict(year.reshape(-1, 1))# 描画
fig, ax = plt.subplots(figsize=(10,5))
ax.plot(year, y_pred1, label="LR")
ax.plot(year, df['Value'], 'k',linewidth=1,label="Actual")
plt.legend()
plt.show()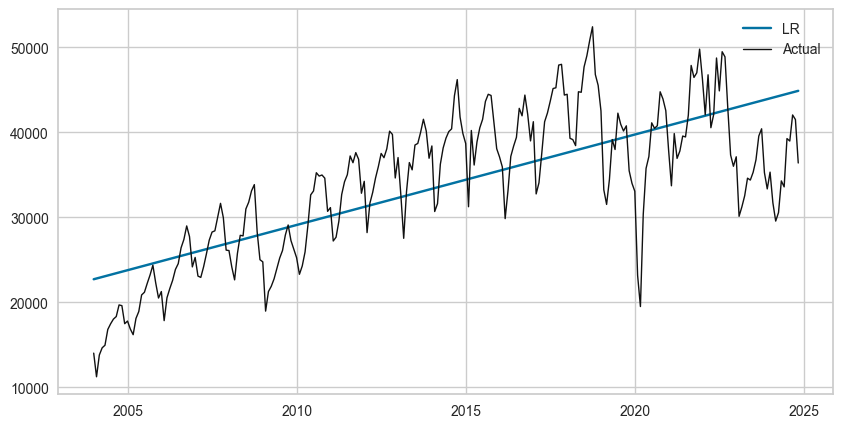
ダミー込み重回帰
# 関税とコロナダミー込みで回帰
model2 = LR()
model2.fit(df.drop(["Date","Value","Tax2"], axis=1), df["Value"])
y_pred2 = model2.predict(df.drop(["Date","Value","Tax2"], axis=1))# 描画
fig, ax = plt.subplots(figsize=(10,5))
ax.plot(year, y_pred1)
ax.plot(year, y_pred2,'g',linewidth=3)
ax.plot(year, df['Value'],'k',linewidth=1)
緑線が、関税とコロナのダミーを入れ予測。ギザギザの直線であるが、季節性やコロナ時の落ち込みの大きな傾向は再現できつつある。
# ダミー込みの場合の残差
plt.scatter(year, df["Value"].values-y_pred2)
plt.title("predict_chronological_linear")
plt.xlabel("year")
plt.ylabel("Residual error")
plt.show()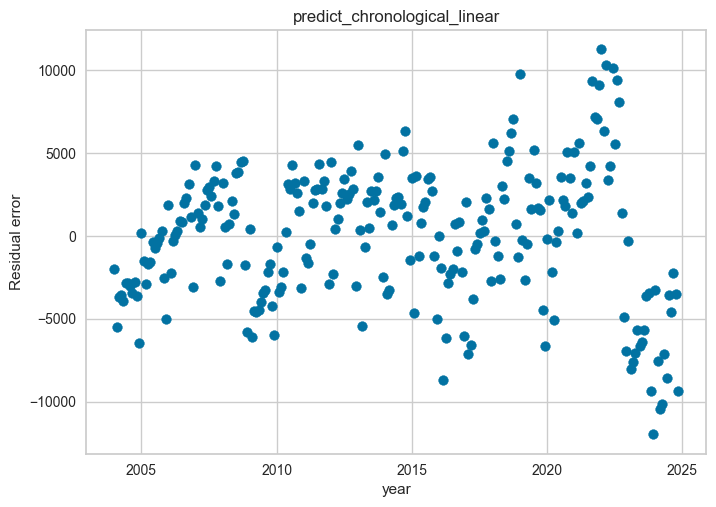
残差はさすがに、まだばらつきが大きく、最大で100億ドルほどあり、輸入額と変わらない。。。
# 係数
coef = np.hstack((model2.coef_, model2.intercept_))
col = df.drop(["Date","Value","Tax2"], axis=1).columns.tolist()
col.append("切片")
dfc = pd.DataFrame(coef)
dfc.index = col
dfc.columns = ["係数"]
この単純なモデルでも、関税の影響を1%上がると15.7億ドル下がり、コロナ禍では130億ドル落ちるとの予測。関税の影響は、他の要因も入るので、この予測と大きくずれていることもあるが、コロナ禍では、実輸入値として、前後で99億ドル、108億ドル落ちているので、単純なダミーでもよい推定になっていると思われる。
重回帰(関税、コロナなし)
次に、関税とコロナダミーなしで重回帰をやってみる。
# Tax、コロナなしモデル
model3 = LR()
model3.fit(df.drop(["Date","Value","Tax","COV19"], axis=1), df["Value"])
y_pred3 = model3.predict(df.drop(["Date","Value","Tax","COV19"], axis=1))# 描画
fig, ax = plt.subplots(figsize=(10,5))
ax.plot(year, df['Value'], 'k',linewidth=1,label="Actual")
ax.plot(year, y_pred1, label="LR")
ax.plot(year, y_pred2,'g',linewidth=2,label='with tax,COV19')
ax.plot(year, y_pred3,'b', linewidth=2, label='Without tax, COV19')
plt.legend()
plt.show()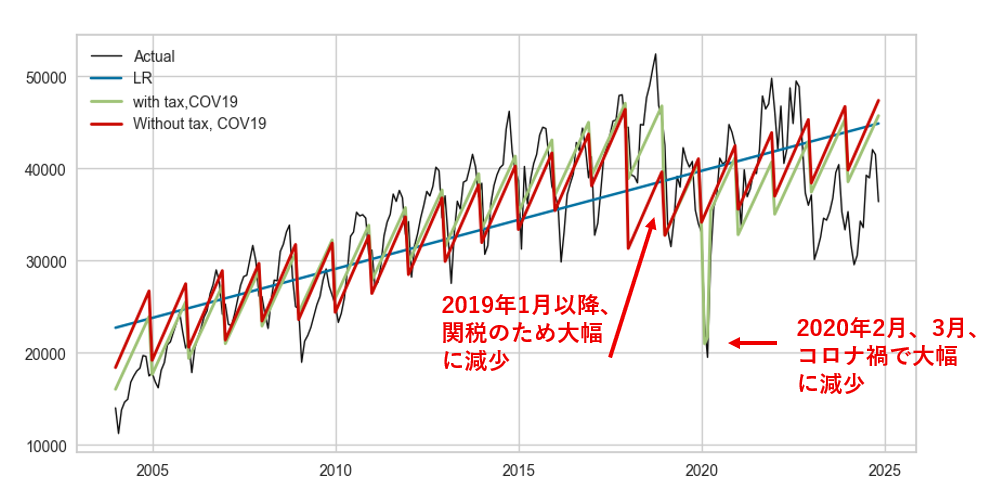
2018年末までの関税率は、3~4%で推移し、2019年1月より、一気に9%以上になっていく。関税なしモデルでは、2019年以降も4%のままという想定でおこなったが、実輸入額が落ちていることから、一旦落ちた後、4%時の成長率で伸びていくモデルとなってしまっている。ただ、実輸入額は、4%時よりもっと急激に伸びていることから、コロナ禍後の回復と成長の速度がもっと大きかったことが考えられる。コロナのダミーは外したことにより、落ち込みはなしという予測はできており、コロナの影響は、この単純なモデルでも排除できると思われる。
関税の影響を図るには、2019年1月以降の落ちた額からの成長ではなく、208年末の輸入額(落ちる前)から、そのまま成長していく予測値(要は、関税がなかった場合の想定)を考える必要があることから、2018年末の輸入額から続けた予測が必要と思われる。
次回、autoMLでの予測をやってみる。
【注記】
データの引用元は、ITC (U.S. International Trade Commission)。
輸出額は、ITC データベースの輸出合計 (Exports: Total)。
輸入額は、後日、関税率などを算定すること等もあり、一般輸入額 (Imports: General)ではなく、消費用輸入額 (Imports: Consumption)の関税評価額(Customs Value)を引用している。